Welcome to our June Data & AI report!
We’re covering some exciting news this month… who knew data catalogs could be so competitive? We’ve also got some interesting updates from NVIDIA and Netflix.
Let’s get stuck in!
Open Source battles: Databricks open sources Unity Catalog…
…live at the Data & AI summit
Following Snowflake’s announcement to open source their Polaris Catalog “within the next 90 days”, Matei Zaharia, Databricks’ CTO & Cofounder, went one up and opened the repo on his laptop during his Keynote speech at the Data & AI summit, navigated to the “danger zone” and in front of everyone, made the repo public there and then. Making Databricks the first to go open source in the industry.

Watch a video of the moment it went live here.
In Databricks’ announcement, they shared the reasoning behind their decision to make this public, explaining that “most data platforms today are walled gardens” going on to say “By open-sourcing Unity Catalog, we are giving organisations an open foundation for their current and future workloads.”
NVIDIA Releases Open Synthetic Data Generation Pipeline for Training LLMs
NVIDIA has launched an open synthetic data generation pipeline for training large language models. The Nemotron-4 340B family offers advanced instruct and reward models, along with a dataset for generative AI training.
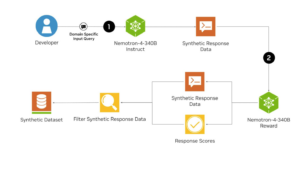
This system provides developers with a free and scalable solution to create synthetic data for building powerful LLMs, enhancing performance and accuracy. The models are designed to work seamlessly with NVIDIA NeMo and TensorRT-LLM for efficient model training and inference.
Netflix share a recap of their Data Engineering Open Forum
Netflix released a summary this month of the sessions from their Data Engineering Open Forum back in April. (along with recordings of all the talks!)
One session introduced Netflix’s “Auto Remediation” feature, which uses machine learning to handle job errors more efficiently. Jide Ogunjobi talked about using generative AI to help organizations easily manage and query their large data systems.
Tulika Bhatt explained how Netflix manages 18 billion daily impressions and the importance of real-time data for recommendations. We found Tulika’s talk particularly interesting as it highlighted the creative solutions Netflix employs to balance scalability and cost while delivering real-time data.
Jessica Larson shared her experience building a new data platform after GDPR, focusing on data protection and compliance. Clark Wright from Airbnb discussed their new Data Quality Score to improve data quality.
You can read about, and watch all of the talks here
How Machine Learning is transforming Online Banking security
Zachary Amos’ recent blog explores how behavioral biometrics can drastically reduce online banking fraud. This ML-driven technology works in the background, monitoring user behavior like mouse movements and keystrokes to spot anything unusual. It processes data in real-time, handling multiple users at once, making it a more streamlined and user-friendly security solution than traditional Multi-Factor Authentication.
Zachary’s insights show the power of machine learning in boosting security. As cyber threats become more sophisticated, using technology like this ensures accounts stay secure and protected.
To conclude
June has been a month full of exciting open-source updates. Databricks made waves by open-sourcing Unity Catalog live on stage, while NVIDIA launched a synthetic data generation pipeline for training large language models.
We’re especially interested in these open-source developments. They represent a move towards greater collaboration and accessibility in the tech world.